
Reinforcement Learning: Cách AI tự học thông qua phần thưởng và sai lầm
Công cụ AI giúp phân tích chi tiết các social audience
- Group Hiệp Hội Sales B2B Toàn Quốc : https://app.thealita.com/526217061602069
- Fanpage The Home Depot: https://app.thealita.com/106485550030
- Profile Cầu Thủ Tuyển Việt Nam Trần Đình Trọng: https://app.thealita.com/100004925382072
Reinforcement Learning: Cách AI tự học thông qua phần thưởng và sai lầm – một khái niệm nghe có vẻ phức tạp nhưng lại là chìa khóa mở ra kỷ nguyên trí tuệ nhân tạo (AI) tự động hóa và thích nghi. Trong vai trò của một biên tập viên chuyên về social data và big data, tôi thường xuyên chứng kiến cách mà dữ liệu khổng lồ trở thành ‘môi trường’ để các thuật toán AI học hỏi và phát triển. Reinforcement Learning, hay còn gọi là Học tăng cường, chính là một trong những phương pháp đột phá nhất, cho phép các hệ thống AI không chỉ xử lý dữ liệu mà còn tương tác, thử nghiệm và rút ra kinh nghiệm từ chính những hành động của mình, từ đó tối ưu hóa hiệu suất theo thời gian. Khác với những phương pháp học máy truyền thống cần dữ liệu được gán nhãn rõ ràng, Reinforcement Learning mô phỏng cách con người và động vật học hỏi: thông qua quá trình thử và sai, nhận về phản hồi dưới dạng phần thưởng hoặc hình phạt, rồi điều chỉnh hành vi để đạt được mục tiêu cuối cùng. Đây không chỉ là một công cụ phân tích mà còn là một kiến trúc tư duy, mở ra cánh cửa cho những ứng dụng AI có khả năng tự ra quyết định trong môi trường phức tạp, từ chơi game đỉnh cao cho đến điều khiển robot và tối ưu hóa hệ thống giao thông đô thị.
Khám phá Reinforcement Learning: Nền tảng của trí tuệ tự học
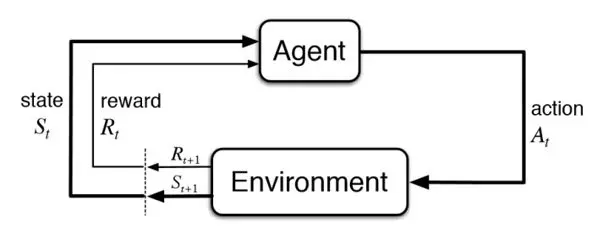
Reinforcement Learning là một lĩnh vực của học máy, tập trung vào việc tạo ra các tác nhân (agent) có khả năng học cách đưa ra chuỗi quyết định tối ưu trong một môi trường cụ thể để tối đa hóa tổng số phần thưởng tích lũy. Triết lý cốt lõi của Reinforcement Learning xoay quanh việc học từ tương tác. Thay vì được huấn luyện bằng các cặp input-output đã được định nghĩa trước như trong học có giám sát, hay tìm kiếm cấu trúc ẩn trong dữ liệu không nhãn như học không giám sát, một tác nhân Reinforcement Learning sẽ chủ động khám phá môi trường của mình. Nó thực hiện các hành động, quan sát kết quả của những hành động đó, nhận được tín hiệu phản hồi dưới dạng phần thưởng hoặc hình phạt, và dần dần xây dựng một chiến lược (policy) để hành động hiệu quả hơn trong tương lai.
Quá trình học hỏi này được định hình bởi bốn yếu tố chính: tác nhân (agent), môi trường (environment), trạng thái (state), hành động (action) và phần thưởng (reward). Tác nhân là thực thể đang học và đưa ra quyết định, ví dụ như một chương trình AI chơi cờ vây. Môi trường là thế giới mà tác nhân tương tác, chẳng hạn như bàn cờ và các luật chơi. Trạng thái là một mô tả về tình hình hiện tại của môi trường, ví dụ như vị trí của các quân cờ. Hành động là những lựa chọn mà tác nhân có thể thực hiện, như di chuyển một quân cờ. Phần thưởng là tín hiệu phản hồi mà tác nhân nhận được sau mỗi hành động, nó có thể là điểm cộng khi thắng một ván cờ hoặc điểm trừ khi thua. Mục tiêu của tác nhân là tìm ra một chiến lược hành động sao cho tổng phần thưởng tích lũy theo thời gian là lớn nhất.
Cơ chế hoạt động của Học tăng cường: Vòng lặp phản hồi không ngừng
Cơ chế hoạt động của Reinforcement Learning diễn ra theo một vòng lặp liên tục, nơi tác nhân liên tục tương tác với môi trường, học hỏi và cải thiện hành vi của mình. Mỗi bước trong vòng lặp này bao gồm việc tác nhân quan sát trạng thái hiện tại của môi trường, sau đó quyết định một hành động dựa trên chiến lược hiện có của nó. Khi hành động được thực hiện, môi trường sẽ chuyển sang một trạng thái mới và cung cấp một phần thưởng (hoặc hình phạt) cho tác nhân. Thông tin về trạng thái mới và phần thưởng này được tác nhân sử dụng để cập nhật chiến lược của mình, làm cho nó trở nên “thông minh” hơn trong lần hành động tiếp theo.
Có nhiều thuật toán khác nhau được sử dụng trong Reinforcement Learning, nhưng một trong những phương pháp phổ biến nhất là Q-learning. Q-learning hoạt động bằng cách xây dựng một bảng giá trị Q (Q-table) lưu trữ giá trị dự kiến của việc thực hiện một hành động cụ thể trong một trạng thái cụ thể. Tức là, Q-table sẽ cho biết mức độ “tốt” của việc thực hiện hành động ‘a’ khi môi trường đang ở trạng thái ‘s’. Tác nhân sẽ học cách cập nhật các giá trị Q này thông qua kinh nghiệm, sử dụng công thức Bellman để tính toán giá trị tương lai của phần thưởng. Một thuật toán khác là SARSA (State-Action-Reward-State-Action) tương tự Q-learning nhưng cập nhật giá trị Q dựa trên hành động tiếp theo được chọn, tạo ra một quá trình học tập “trên chính sách” (on-policy). Những phương pháp này cùng với các biến thể của chúng, thường được kết hợp với mạng nơ-ron sâu (Deep Reinforcement Learning) để xử lý các môi trường có không gian trạng thái và hành động lớn, mở rộng đáng kể khả năng ứng dụng của Reinforcement Learning.
Ứng dụng đa dạng của Reinforcement Learning: Từ trò chơi đến thế giới thực
Khả năng tự học và thích nghi của Reinforcement Learning đã mở ra cánh cửa cho hàng loạt ứng dụng đột phá, vượt xa các giới hạn của AI truyền thống. Một trong những minh chứng rõ ràng nhất là trong lĩnh vực trò chơi điện tử, nơi AI đã đạt được những thành tích phi thường. Ví dụ điển hình nhất là AlphaGo của DeepMind, đã đánh bại nhà vô địch cờ vây thế giới Lee Sedol, một thành tựu mà giới chuyên gia từng cho rằng phải mất hàng thập kỷ nữa mới có thể đạt được. AlphaGo đã tự học thông qua hàng triệu ván đấu với chính nó, phát triển những chiến lược mà ngay cả con người cũng chưa từng nghĩ đến. Tương tự, trong các trò chơi điện tử khác như StarCraft II hay Dota 2, các tác nhân Reinforcement Learning cũng đã chứng tỏ khả năng vượt trội so với người chơi chuyên nghiệp, cho thấy tiềm năng của phương pháp này trong việc giải quyết các bài toán phức tạp với không gian trạng thái và hành động khổng lồ.
Ngoài trò chơi, Reinforcement Learning đang dần thay đổi nhiều ngành công nghiệp khác. Trong lĩnh vực robot, nó cho phép robot học cách di chuyển, cầm nắm vật thể hoặc thực hiện các tác vụ phức tạp trong môi trường không xác định mà không cần lập trình rõ ràng từng bước. Các robot có thể tự học cách đi lại hoặc thực hiện các thao tác lắp ráp thông qua việc thử nghiệm và nhận phản hồi từ môi trường vật lý. Một ứng dụng tiềm năng lớn khác là trong lĩnh vực xe tự lái, nơi Reinforcement Learning có thể giúp xe học cách điều hướng an toàn trong các tình huống giao thông phức tạp, dự đoán hành vi của người lái khác và tối ưu hóa lộ trình. Ngay cả trong lĩnh vực tài chính, các thuật toán Reinforcement Learning cũng đang được nghiên cứu để tối ưu hóa chiến lược giao dịch, quản lý danh mục đầu tư hay phát hiện gian lận bằng cách học hỏi từ biến động thị trường và các mẫu hành vi bất thường.
Thách thức và tiềm năng phát triển của Reinforcement Learning
Mặc dù Reinforcement Learning đã đạt được những bước tiến đáng kinh ngạc, nhưng nó vẫn đối mặt với nhiều thách thức cần được giải quyết để phát huy hết tiềm năng. Một trong những thách thức lớn nhất là vấn đề hiệu quả dữ liệu. Các thuật toán Reinforcement Learning thường yêu cầu một lượng lớn tương tác với môi trường để học hỏi hiệu quả, điều này có thể tốn kém và mất thời gian, đặc biệt trong các môi trường thực tế như robot hoặc xe tự lái, nơi việc thử nghiệm trực tiếp có thể gây nguy hiểm. Việc thu thập dữ liệu chất lượng cao từ các tương tác này cũng là một rào cản, đặc biệt khi các phần thưởng không rõ ràng hoặc bị trì hoãn.
Một thách thức khác là vấn đề “khám phá và khai thác” (exploration-exploitation dilemma). Tác nhân Reinforcement Learning cần phải cân bằng giữa việc khám phá các hành động mới để tìm ra chiến lược tốt hơn và khai thác các hành động đã biết để nhận phần thưởng tối đa. Nếu khám phá quá ít, tác nhân có thể mắc kẹt trong một chiến lược cục bộ không tối ưu. Nếu khám phá quá nhiều, nó có thể lãng phí thời gian và nguồn lực vào những hành động không hiệu quả. Ngoài ra, việc thiết kế hàm phần thưởng (reward function) phù hợp là vô cùng quan trọng nhưng cũng rất khó khăn. Một hàm phần thưởng không được thiết kế tốt có thể dẫn đến hành vi không mong muốn hoặc khó kiểm soát của tác nhân AI. Tính minh bạch và khả năng giải thích (interpretability) của các mô hình Reinforcement Learning phức tạp, đặc biệt là khi kết hợp với học sâu, cũng là một vấn đề cần được cải thiện để tăng cường sự tin cậy và ứng dụng rộng rãi.
Tương lai của Reinforcement Learning trong kỷ nguyên dữ liệu lớn và AI
Trong kỷ nguyên dữ liệu lớn (Big Data) và sự phát triển không ngừng của trí tuệ nhân tạo, Reinforcement Learning hứa hẹn sẽ đóng một vai trò ngày càng quan trọng. Với khả năng xử lý lượng dữ liệu khổng lồ từ các tương tác liên tục, các hệ thống Reinforcement Learning sẽ trở nên thông minh hơn, thích nghi tốt hơn với môi trường thay đổi và đưa ra quyết định tối ưu trong các tình huống phức tạp. Sự kết hợp giữa Reinforcement Learning với các kỹ thuật học sâu (Deep Learning), tạo ra Deep Reinforcement Learning, đã chứng tỏ hiệu quả vượt trội trong việc giải quyết các bài toán có không gian trạng thái và hành động lớn, mở rộng phạm vi ứng dụng từ các trò chơi đến điều khiển công nghiệp và chăm sóc sức khỏe.
Một trong những xu hướng phát triển đáng chú ý là học tăng cường ngoại tuyến (Offline Reinforcement Learning) hoặc học từ dữ liệu tĩnh (Batch Reinforcement Learning), nơi tác nhân học từ một tập dữ liệu đã thu thập trước đó mà không cần tương tác trực tiếp với môi trường. Điều này giúp giải quyết vấn đề hiệu quả dữ liệu và giảm thiểu rủi ro trong các môi trường thực tế. Ngoài ra, Reinforcement Learning đang được tích hợp vào các hệ thống đề xuất cá nhân hóa, tối ưu hóa trải nghiệm người dùng trên các nền tảng mạng xã hội và thương mại điện tử bằng cách học hỏi từ hành vi và sở thích của người dùng để đưa ra các gợi ý phù hợp nhất. Khi dữ liệu ngày càng trở nên phong phú và đa chiều, khả năng tự học của AI thông qua Reinforcement Learning sẽ không ngừng mở rộng, kiến tạo nên một tương lai nơi công nghệ không chỉ phản ứng mà còn chủ động định hình thế giới của chúng ta một cách thông minh và hiệu quả hơn bao giờ hết.

{kind=link}