
Data Pipeline – Dòng chảy dữ liệu nuôi sống các hệ thống AI
Một vài phân tích Persona Insight cho AI thực hiện:
- 1. Tấn Tài : https://app.thealita.com/insight/IWZ9Z097
- 2. Nam Nguyen: https://app.thealita.com/insight/IWZ9Z086
- 3. Duy Nguyen : https://app.thealita.com/insight/IWZ9Z09C
Data Pipeline, như tên gọi, là một dòng chảy không ngừng nghỉ, nơi dữ liệu được thu thập, xử lý, chuyển đổi và đưa đến điểm đích cuối cùng, sẵn sàng cho việc phân tích hoặc cung cấp năng lượng cho các ứng dụng. Trong bối cảnh bùng nổ của social data và sự phát triển vượt bậc của big data, khái niệm Data Pipeline đã trở thành xương sống, là yếu tố then chốt quyết định sự thành bại của mọi hệ thống thông minh, đặc biệt là các hệ thống Trí tuệ Nhân tạo (AI). Nếu coi AI là bộ não của kỷ nguyên số, thì Data Pipeline chính là hệ tuần hoàn, không ngừng vận chuyển dòng máu dữ liệu tinh khiết và dồi dào để nuôi dưỡng và duy trì sự sống cho bộ não đó, giúp nó học hỏi, thích nghi và đưa ra quyết định một cách hiệu quả nhất. Không có một Data Pipeline được thiết kế và vận hành tốt, dữ liệu sẽ chỉ là một khối hỗn độn không giá trị, không thể nào phát huy được tiềm năng to lớn của nó.
Định nghĩa Data Pipeline và tầm quan trọng trong kỷ nguyên số
Data Pipeline là một chuỗi các bước được tự động hóa để di chuyển dữ liệu từ nguồn này sang nguồn khác, đồng thời xử lý và chuyển đổi dữ liệu trên đường đi. Nó bao gồm nhiều giai đoạn như thu thập, làm sạch, chuyển đổi, tích hợp và lưu trữ dữ liệu. Trong kỷ nguyên số, khi lượng dữ liệu sinh ra mỗi giây đạt mức khổng lồ, đặc biệt là từ các nền tảng mạng xã hội (social data), tầm quan trọng của Data Pipeline trở nên không thể phủ nhận. Nó đảm bảo rằng các tổ chức có thể tiếp cận dữ liệu một cách kịp thời và đáng tin cậy, biến dữ liệu thô thành thông tin có giá trị, hỗ trợ ra quyết định nhanh chóng và chính xác.
Vai trò của Data Pipeline trong việc “nuôi sống” các hệ thống AI
Hệ thống AI, dù là học máy (Machine Learning) hay học sâu (Deep Learning), đều phụ thuộc hoàn toàn vào dữ liệu để huấn luyện và hoạt động. Một Data Pipeline hiệu quả sẽ đảm bảo rằng các mô hình AI nhận được dữ liệu chất lượng cao, được chuẩn hóa và cập nhật liên tục. Từ dữ liệu khách hàng, hành vi người dùng trên mạng xã hội cho đến các cảm biến IoT, mọi thông tin đều cần được xử lý và phân phối đúng lúc để AI có thể đưa ra dự đoán chính xác, cá nhân hóa trải nghiệm người dùng, phát hiện gian lận hay tự động hóa các quy trình phức tạp. Nếu Data Pipeline tắc nghẽn hoặc cung cấp dữ liệu sai lệch, các mô hình AI sẽ hoạt động kém hiệu quả, thậm chí đưa ra những quyết định sai lầm, gây hậu quả nghiêm trọng.
Từ Social Data đến Big Data: Nền tảng cho Data Pipeline hiệu quả
Social data, với đặc tính phi cấu trúc, khối lượng lớn và tốc độ phát sinh nhanh, là một thách thức lớn nhưng cũng là một nguồn tài nguyên quý giá cho Data Pipeline. Việc trích xuất insight từ hàng tỷ bài đăng, bình luận, lượt thích mỗi ngày đòi hỏi một Data Pipeline có khả năng xử lý Big Data vượt trội. Từ việc thu thập dữ liệu về xu hướng thị trường, tâm lý khách hàng, cho đến việc phân tích hành vi người dùng để cải thiện sản phẩm, Data Pipeline phải được thiết kế để xử lý không chỉ dữ liệu có cấu trúc mà còn cả dữ liệu bán cấu trúc và phi cấu trúc, đảm bảo rằng mọi mảnh ghép thông tin đều được đưa vào đúng vị trí, phục vụ mục tiêu cuối cùng là tạo ra giá trị kinh doanh.
Cấu trúc và các thành phần cốt lõi của một Data Pipeline hiệu quả
Một Data Pipeline được thiết kế tốt không chỉ đơn thuần là việc di chuyển dữ liệu, mà là một hệ thống phức tạp với nhiều giai đoạn và thành phần phối hợp nhịp nhàng. Mỗi bước trong Data Pipeline đều có vai trò quan trọng, từ việc nắm bắt dữ liệu ở nguồn cho đến việc phân phối dữ liệu đã xử lý đến các ứng dụng cuối cùng. Việc hiểu rõ các thành phần này là chìa khóa để xây dựng một Data Pipeline mạnh mẽ, đáng tin cậy và có khả năng mở rộng, đáp ứng được nhu cầu ngày càng tăng của dữ liệu lớn và các hệ thống AI hiện đại.
Thu thập dữ liệu: Điểm khởi đầu của mọi Data Pipeline
Giai đoạn thu thập là bước đầu tiên và cơ bản nhất của bất kỳ Data Pipeline nào. Tại đây, dữ liệu được trích xuất từ các nguồn khác nhau, có thể là cơ sở dữ liệu quan hệ, file log, API của các nền tảng mạng xã hội, thiết bị IoT, hay các hệ thống ERP/CRM. Mục tiêu là đảm bảo mọi dữ liệu liên quan được thu thập đầy đủ và kịp thời. Đối với social data, điều này có thể bao gồm việc sử dụng các công cụ crawling hoặc API của Twitter, Facebook, Instagram để lấy về các bài đăng, bình luận, thông tin hồ sơ người dùng. Các công nghệ phổ biến ở giai đoạn này bao gồm Apache Kafka để thu thập dữ liệu streaming theo thời gian thực hoặc công cụ ETL truyền thống cho dữ liệu batch.
Chuyển đổi và xử lý dữ liệu: Tạo giá trị từ dữ liệu thô
Sau khi được thu thập, dữ liệu thô thường không sẵn sàng để sử dụng ngay. Giai đoạn chuyển đổi và xử lý là nơi dữ liệu được làm sạch, chuẩn hóa, tổng hợp, và chuyển đổi sang định dạng phù hợp. Điều này có thể bao gồm việc loại bỏ dữ liệu trùng lặp, xử lý giá trị thiếu, chuẩn hóa định dạng ngày tháng, hoặc trích xuất thông tin cụ thể từ văn bản phi cấu trúc (ví dụ: phân tích cảm xúc từ bình luận mạng xã hội). Quá trình này thường được gọi là ETL (Extract, Transform, Load) hoặc ELT (Extract, Load, Transform), tùy thuộc vào vị trí thực hiện bước chuyển đổi. Các công cụ như Apache Spark, Flink, hay các dịch vụ đám mây như AWS Glue, Google Dataflow đóng vai trò thiết yếu trong việc thực hiện các phép biến đổi phức tạp trên quy mô lớn.
Lưu trữ và cung cấp dữ liệu: Đảm bảo khả năng truy cập và sử dụng
Bước cuối cùng của Data Pipeline là lưu trữ dữ liệu đã được xử lý và làm sạch vào một kho lưu trữ đích, nơi nó có thể được truy cập bởi các ứng dụng phân tích, báo cáo hoặc các mô hình AI. Kho lưu trữ này có thể là một data warehouse, data lake, cơ sở dữ liệu NoSQL, hoặc một hệ thống lưu trữ đối tượng đám mây. Việc lựa chọn phương pháp lưu trữ phụ thuộc vào yêu cầu về tốc độ truy vấn, khối lượng dữ liệu, và cấu trúc dữ liệu. Hơn nữa, Data Pipeline cũng chịu trách nhiệm cung cấp dữ liệu này đến các hệ thống tiêu thụ, có thể thông qua API, message queues, hoặc tích hợp trực tiếp với các nền tảng AI/BI, đảm bảo dữ liệu luôn sẵn sàng khi cần thiết.
Data Pipeline trong bối cảnh Social Data và Big Data: Thách thức và cơ hội
Trong kỷ nguyên của thông tin siêu tốc và bùng nổ dữ liệu, việc xây dựng một Data Pipeline hiệu quả để xử lý social data và big data không chỉ là một nhu cầu mà còn là một lợi thế cạnh tranh then chốt. Những đặc điểm cố hữu của hai loại dữ liệu này đặt ra nhiều thách thức nhưng đồng thời cũng mở ra vô vàn cơ hội cho các tổ chức biết cách khai thác. Data Pipeline phải đủ linh hoạt và mạnh mẽ để đối phó với sự đa dạng, khối lượng, và tốc độ của dữ liệu, đồng thời đảm bảo chất lượng và tính bảo mật của thông tin.
Xử lý dữ liệu phi cấu trúc từ mạng xã hội: Một bài toán phức tạp
Social data chủ yếu là dữ liệu phi cấu trúc như văn bản, hình ảnh, video, audio. Việc trích xuất thông tin có giá trị từ những dạng dữ liệu này đòi hỏi Data Pipeline phải tích hợp các công nghệ xử lý ngôn ngữ tự nhiên (NLP), thị giác máy tính (Computer Vision) và học sâu. Ví dụ, để hiểu cảm xúc của người dùng từ các bình luận trên Twitter, Data Pipeline cần phải có khả năng thực hiện phân tích cảm xúc (sentiment analysis), nhận dạng thực thể có tên (named entity recognition) hay phân loại văn bản. Thách thức không chỉ nằm ở việc xử lý dữ liệu phi cấu trúc mà còn ở việc chuẩn hóa và tích hợp nó với các dữ liệu có cấu trúc khác để tạo ra một cái nhìn toàn diện.
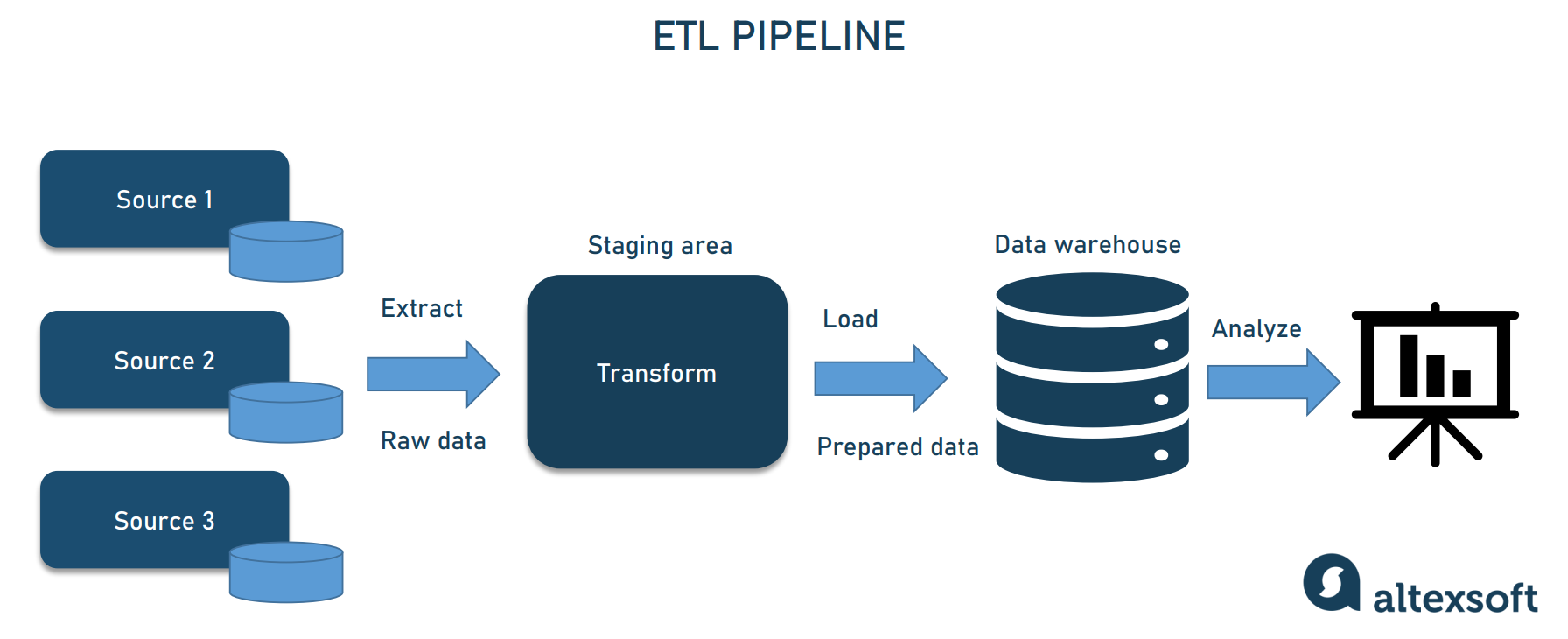
Tốc độ và quy mô: Yêu cầu không thể thiếu với Big Data Pipeline
Big data đặc trưng bởi ba chữ V: Volume (khối lượng), Velocity (tốc độ) và Variety (đa dạng). Một Big Data Pipeline phải có khả năng xử lý hàng terabyte, thậm chí petabyte dữ liệu mỗi ngày, với tốc độ gần như thời gian thực. Điều này đòi hỏi kiến trúc phân tán mạnh mẽ, sử dụng các công nghệ như Apache Hadoop, Apache Spark, và các hệ thống lưu trữ đối tượng có khả năng mở rộng linh hoạt như Amazon S3, Google Cloud Storage. Data Pipeline cần được thiết kế để có thể mở rộng theo chiều ngang (scale horizontally) khi lượng dữ liệu tăng lên, đảm bảo hiệu suất không bị suy giảm và thông tin luôn được cập nhật một cách nhanh chóng nhất.
Đảm bảo chất lượng và tính nhất quán của dữ liệu lớn
Với khối lượng dữ liệu khổng lồ và đa dạng nguồn, việc đảm bảo chất lượng và tính nhất quán của dữ liệu là một thách thức lớn. Dữ liệu có thể chứa lỗi, thiếu sót, hoặc không nhất quán về định dạng. Một Data Pipeline hiệu quả phải tích hợp các bước kiểm tra chất lượng dữ liệu (data quality checks), làm sạch (data cleansing) và xác thực (data validation) liên tục trong suốt quá trình xử lý. Điều này không chỉ giúp tránh việc đưa dữ liệu “rác” vào các hệ thống AI mà còn đảm bảo rằng các phân tích và quyết định được đưa ra dựa trên thông tin chính xác và đáng tin cậy.
Các mô hình và công nghệ tiêu biểu hỗ trợ Data Pipeline hiện đại
Sự phát triển của công nghệ đã mang lại nhiều mô hình và công cụ mạnh mẽ, giúp các tổ chức xây dựng và vận hành Data Pipeline một cách hiệu quả hơn, đặc biệt trong bối cảnh social data và big data. Từ việc xử lý dữ liệu theo thời gian thực cho đến việc sử dụng các kiến trúc linh hoạt và công nghệ mã nguồn mở, những tiến bộ này đang định hình cách chúng ta tiếp cận và khai thác dữ liệu. Việc lựa chọn công nghệ và mô hình phù hợp là yếu tố quyết định sự thành công của một Data Pipeline.
Data Pipeline thời gian thực (Real-time Data Pipeline) cho phản ứng tức thì
Trong nhiều trường hợp, đặc biệt là với social data, khả năng phản ứng tức thì là cực kỳ quan trọng. Ví dụ, việc theo dõi xu hướng trên mạng xã hội, phát hiện gian lận trong giao dịch tài chính, hay cá nhân hóa trải nghiệm khách hàng đòi hỏi dữ liệu phải được xử lý và phân tích ngay lập tức khi nó phát sinh. Real-time Data Pipeline sử dụng các công nghệ xử lý streaming như Apache Kafka, Apache Flink, Apache Storm để thu thập, xử lý và phân phối dữ liệu với độ trễ thấp nhất. Điều này cho phép các hệ thống AI đưa ra quyết định hoặc hành động ngay lập tức, mang lại lợi thế cạnh tranh đáng kể.
Kiến trúc Lambda và Kappa: Các phương pháp tiếp cận linh hoạt
Kiến trúc Lambda là một mô hình thiết kế Data Pipeline xử lý cả dữ liệu batch (theo lô) và dữ liệu streaming (theo luồng). Nó bao gồm một lớp batch để xử lý dữ liệu lịch sử và một lớp tốc độ (speed layer) để xử lý dữ liệu thời gian thực. Kết quả từ hai lớp này được hợp nhất tại lớp phục vụ (serving layer). Kiến trúc Kappa đơn giản hóa Lambda bằng cách xử lý tất cả dữ liệu như một luồng sự kiện duy nhất, loại bỏ lớp batch riêng biệt. Cả hai kiến trúc đều cung cấp sự linh hoạt và khả năng mở rộng để xử lý big data, cho phép các tổ chức chọn lựa mô hình phù hợp nhất với yêu cầu về độ chính xác và độ trễ của họ.
Công nghệ nguồn mở và điện toán đám mây: Sức mạnh của sự kết hợp
Sự kết hợp giữa công nghệ nguồn mở và điện toán đám mây đã cách mạng hóa việc xây dựng Data Pipeline. Các framework nguồn mở như Apache Hadoop, Apache Spark, Apache Kafka, Apache Flink cung cấp nền tảng vững chắc cho việc xử lý dữ liệu lớn. Điện toán đám mây (AWS, Google Cloud, Azure) cung cấp khả năng mở rộng không giới hạn, chi phí hiệu quả và các dịch vụ quản lý giúp đơn giản hóa việc triển khai và vận hành Data Pipeline. Các dịch vụ như AWS Kinesis, Google Pub/Sub, Azure Event Hubs cung cấp các giải pháp streaming dữ liệu dễ dàng tích hợp, trong khi các dịch vụ data lake và data warehouse trên đám mây giúp lưu trữ và phân tích dữ liệu một cách hiệu quả.
Tối ưu Data Pipeline: Chìa khóa nâng cao hiệu suất AI và kinh doanh
Việc xây dựng một Data Pipeline thôi là chưa đủ; việc tối ưu hóa nó liên tục là yếu tố sống còn để đảm bảo các hệ thống AI hoạt động ở mức cao nhất và các quyết định kinh doanh được dựa trên dữ liệu chính xác và kịp thời. Một Data Pipeline được tối ưu hóa tốt không chỉ nâng cao hiệu suất mà còn giảm thiểu chi phí vận hành, cải thiện độ tin cậy và tăng cường bảo mật dữ liệu. Đây là một quá trình liên tục đòi hỏi sự giám sát chặt chẽ, tự động hóa thông minh và quản lý dữ liệu toàn diện.
Giám sát và bảo trì: Đảm bảo Data Pipeline vận hành trơn tru
Data Pipeline là một hệ thống động, luôn cần được giám sát để phát hiện sớm các sự cố, tắc nghẽn hoặc lỗi dữ liệu. Việc triển khai các công cụ giám sát hiệu suất (performance monitoring tools) và hệ thống cảnh báo (alerting systems) là rất quan trọng để đảm bảo Data Pipeline luôn hoạt động trơn tru. Bảo trì định kỳ bao gồm việc cập nhật phần mềm, tối ưu hóa các script xử lý, và điều chỉnh cấu hình để thích ứng với sự thay đổi của nguồn dữ liệu hoặc yêu cầu của hệ thống AI. Giám sát không chỉ giúp khắc phục sự cố mà còn cung cấp insight để cải thiện hiệu quả tổng thể của Data Pipeline.
Tự động hóa và quản lý metadata: Giảm thiểu công sức thủ công
Tự động hóa là yếu tố then chốt để quản lý Data Pipeline phức tạp, đặc biệt với khối lượng big data khổng lồ. Việc tự động hóa các tác vụ như lập lịch chạy (scheduling), xử lý lỗi (error handling), và triển khai (deployment) giúp giảm thiểu lỗi của con người và giải phóng đội ngũ kỹ sư khỏi các công việc lặp đi lặp lại. Quản lý metadata (siêu dữ liệu) cũng đóng vai trò quan trọng, cung cấp thông tin về nguồn gốc dữ liệu, lịch sử chuyển đổi, và cấu trúc dữ liệu, giúp dễ dàng theo dõi, kiểm soát và hiểu rõ Data Pipeline. Các công cụ quản lý luồng công việc (workflow orchestration tools) như Apache Airflow là ví dụ điển hình cho việc tự động hóa và quản lý hiệu quả.
Tích hợp bảo mật và quản lý quyền truy cập dữ liệu
Trong một Data Pipeline, dữ liệu di chuyển qua nhiều giai đoạn và được lưu trữ ở nhiều nơi, do đó bảo mật là một yếu tố không thể bỏ qua. Việc tích hợp các biện pháp bảo mật như mã hóa dữ liệu khi truyền tải và khi lưu trữ (encryption in transit and at rest), kiểm soát truy cập dựa trên vai trò (role-based access control), và kiểm toán (auditing) là cần thiết để bảo vệ thông tin nhạy cảm. Quản lý quyền truy cập dữ liệu một cách chặt chẽ đảm bảo rằng chỉ những người dùng và hệ thống được ủy quyền mới có thể truy cập và sử dụng dữ liệu, tuân thủ các quy định về quyền riêng tư và bảo mật thông tin.
Data Pipeline không chỉ là một công nghệ mà là một triết lý về cách chúng ta tiếp cận và khai thác dữ liệu trong kỷ nguyên số. Nó là huyết mạch nuôi dưỡng sự sống cho mọi hệ thống AI, từ những chatbot đơn giản đến những thuật toán học sâu phức tạp nhất, cho phép chúng ta biến dữ liệu thô thành trí tuệ và tạo ra những giá trị đột phá. Việc đầu tư vào một Data Pipeline mạnh mẽ, linh hoạt và được tối ưu hóa không còn là lựa chọn mà là một yêu cầu bắt buộc đối với bất kỳ tổ chức nào muốn thành công trong bối cảnh cạnh tranh khốc liệt của thế giới dựa trên dữ liệu.

{kind=link}