
AI Model Training – Quy trình huấn luyện để tạo nên trí tuệ nhân tạo
Công cụ AI giúp phân tích chi tiết các social audience
- Group Hiệp Hội Sales B2B Toàn Quốc : https://app.thealita.com/526217061602069
- Fanpage The Home Depot: https://app.thealita.com/106485550030
- Profile Cầu Thủ Tuyển Việt Nam Trần Đình Trọng: https://app.thealita.com/100004925382072
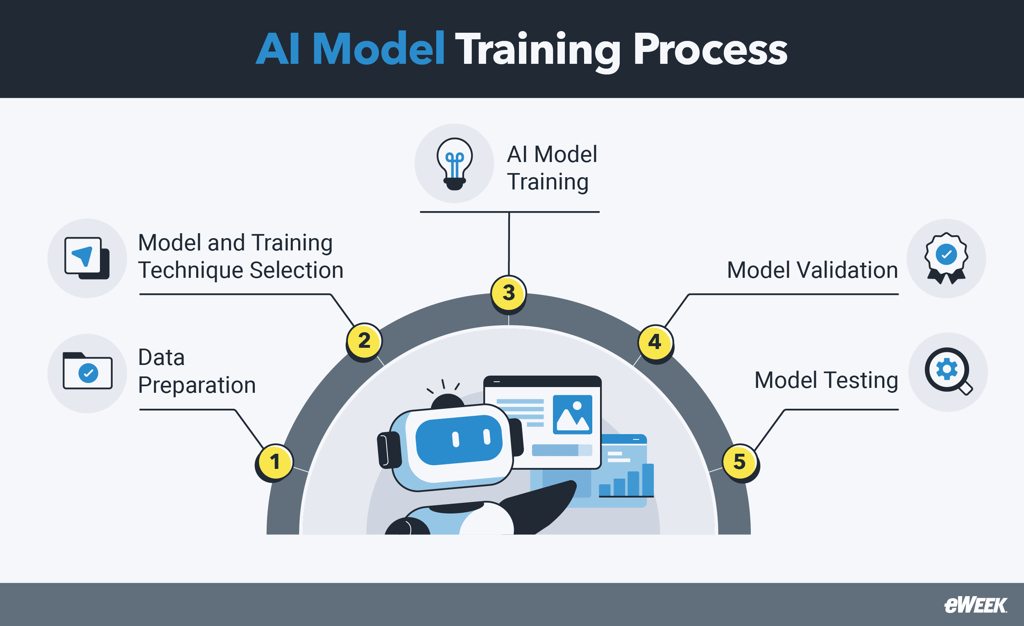
AI Model Training – Quy trình huấn luyện để tạo nên trí tuệ nhân tạo là một hành trình phức tạp nhưng đầy hấp dẫn, nơi dữ liệu thô được biến hóa thành trí thông minh nhân tạo có khả năng học hỏi, suy luận và đưa ra quyết định. Trong bối cảnh kỷ nguyên số bùng nổ, sự phát triển vượt bậc của trí tuệ nhân tạo (AI) đã và đang định hình lại cách chúng ta tương tác với thế giới, từ các ứng dụng cá nhân đến những giải pháp công nghiệp quy mô lớn. Để đạt được những bước tiến thần tốc này, quy trình AI Model Training đóng vai trò then chốt, là xương sống giúp các mô hình học máy đạt được hiệu suất tối ưu và khả năng thích ứng linh hoạt. Nó không chỉ đơn thuần là việc “dạy” máy tính, mà còn là một nghệ thuật kết hợp giữa khoa học dữ liệu, kỹ thuật lập trình và sự hiểu biết sâu sắc về lĩnh vực ứng dụng.
Nền tảng của AI Model Training: Dữ liệu là vàng
Dữ liệu không chỉ là nguyên liệu thô mà còn là trái tim của mọi mô hình AI. Không có dữ liệu chất lượng, bất kỳ quy trình AI Model Training nào cũng sẽ gặp phải những giới hạn đáng kể, thậm chí là thất bại hoàn toàn. Dữ liệu chính là “thức ăn” giúp AI học hỏi, nhận biết các mẫu, mối quan hệ và đưa ra dự đoán chính xác.
Thu thập và chuẩn bị dữ liệu: Bước đi chiến lược đầu tiên
Bước đầu tiên và cũng là một trong những bước quan trọng nhất trong AI Model Training là thu thập và chuẩn bị dữ liệu. Điều này đòi hỏi một chiến lược rõ ràng để đảm bảo rằng dữ liệu không chỉ đủ lớn về số lượng mà còn phải đa dạng và đại diện cho vấn đề cần giải quyết. Dữ liệu có thể đến từ nhiều nguồn khác nhau như cơ sở dữ liệu có sẵn, cảm biến, các tương tác người dùng, hình ảnh, văn bản hoặc âm thanh. Sau khi thu thập, dữ liệu cần được làm sạch, tức là loại bỏ các giá trị nhiễu, trùng lặp, thiếu sót hoặc không nhất quán. Quy trình này thường bao gồm việc điền các giá trị bị thiếu, chuẩn hóa dữ liệu, mã hóa các biến phân loại và loại bỏ ngoại lai. Việc tiền xử lý dữ liệu cẩn thận sẽ giúp mô hình học hiệu quả hơn và tránh được những sai lệch không mong muốn.
Đánh giá chất lượng dữ liệu: Yếu tố quyết định thành công
Chất lượng dữ liệu được đánh giá dựa trên nhiều tiêu chí như độ chính xác, độ hoàn chỉnh, tính nhất quán, tính kịp thời và tính liên quan. Dữ liệu kém chất lượng có thể dẫn đến một mô hình AI đưa ra các dự đoán sai lệch, hoạt động không ổn định hoặc thậm chí là thiên vị. Các chuyên gia cần dành thời gian để phân tích dữ liệu, khám phá các mối quan hệ ẩn giấu và xác định bất kỳ vấn đề tiềm ẩn nào trước khi đưa vào huấn luyện. Việc đảm bảo chất lượng dữ liệu không chỉ giúp mô hình học hiệu quả hơn mà còn tăng cường độ tin cậy và khả năng giải thích của hệ thống AI.
Các phương pháp huấn luyện mô hình AI cốt lõi
AI Model Training được thực hiện thông qua nhiều phương pháp khác nhau, mỗi phương pháp có những ưu điểm và ứng dụng riêng biệt, phù hợp với các loại bài toán khác nhau. Việc lựa chọn phương pháp huấn luyện phù hợp là yếu tố then chốt để đạt được hiệu suất mong muốn.
Học có giám sát (Supervised Learning): Từ ví dụ đến hiểu biết
Học có giám sát là phương pháp phổ biến nhất trong AI Model Training, nơi mô hình học từ một tập dữ liệu đã được gán nhãn, tức là mỗi đầu vào đều có một đầu ra mong muốn tương ứng. Ví dụ, trong bài toán phân loại hình ảnh, mô hình sẽ được cung cấp hàng ngàn hình ảnh đã được gán nhãn là “mèo” hoặc “chó”. Mục tiêu của mô hình là học được mối quan hệ giữa đầu vào (hình ảnh) và đầu ra (nhãn) để có thể dự đoán nhãn cho các hình ảnh mới chưa từng thấy. Các thuật toán học có giám sát bao gồm hồi quy tuyến tính, hồi quy logistic, máy véc tơ hỗ trợ (SVM), cây quyết định và mạng nơ-ron truyền thẳng. Phương pháp này rất hiệu quả cho các bài toán dự đoán và phân loại rõ ràng.
Học không giám sát (Unsupervised Learning): Khám phá cấu trúc ẩn
Ngược lại với học có giám sát, học không giám sát hoạt động với dữ liệu chưa được gán nhãn. Mục tiêu của nó là tìm kiếm các cấu trúc ẩn, mối quan hệ hoặc các nhóm tự nhiên trong dữ liệu. Ví dụ, trong phân tích thị trường, học không giám sát có thể giúp phân nhóm khách hàng thành các phân khúc khác nhau dựa trên hành vi mua sắm của họ mà không cần biết trước các phân khúc đó là gì. Các thuật toán phổ biến bao gồm k-means clustering, phân tích thành phần chính (PCA) và mô hình Gaussian mixture. Phương pháp này đặc biệt hữu ích cho các bài toán khám phá dữ liệu, giảm chiều dữ liệu và phát hiện bất thường.
Học tăng cường (Reinforcement Learning): Học thông qua trải nghiệm
Học tăng cường là một phương pháp huấn luyện mô hình AI độc đáo, nơi một tác nhân (agent) học cách đưa ra quyết định thông qua tương tác với môi trường. Tác nhân nhận được “phần thưởng” (reward) khi thực hiện các hành động tốt và “hình phạt” (penalty) khi thực hiện các hành động kém. Qua hàng ngàn, thậm chí hàng triệu lần thử và sai, tác nhân dần học được chính sách tối ưu để tối đa hóa tổng phần thưởng. Ví dụ điển hình là các hệ thống AI chơi game như AlphaGo, hoặc các robot tự lái. Học tăng cường rất phù hợp cho các bài toán đòi hỏi ra quyết định liên tục trong môi trường động.
Lựa chọn và điều chỉnh kiến trúc mô hình AI
Sau khi có dữ liệu và hiểu rõ các phương pháp huấn luyện, bước tiếp theo trong AI Model Training là lựa chọn và điều chỉnh kiến trúc mô hình phù hợp nhất với bài toán và dữ liệu. Đây là một quá trình vừa khoa học vừa mang tính nghệ thuật, đòi hỏi sự hiểu biết sâu sắc về các thuật toán và khả năng thử nghiệm liên tục.
Chọn lựa thuật toán phù hợp: Tối ưu hóa cho mục tiêu
Việc lựa chọn thuật toán phù hợp phụ thuộc vào nhiều yếu tố: loại dữ liệu (có cấu trúc, phi cấu trúc), quy mô dữ liệu, độ phức tạp của bài toán, yêu cầu về hiệu suất và khả năng giải thích của mô hình. Chẳng hạn, mạng nơ-ron tích chập (CNN) rất hiệu quả cho các bài toán xử lý hình ảnh, trong khi mạng nơ-ron hồi quy (RNN) hay Transformer lại phù hợp với dữ liệu chuỗi thời gian và xử lý ngôn ngữ tự nhiên. Đối với các bài toán đơn giản hơn, các thuật toán truyền thống như cây quyết định hoặc SVM có thể là lựa chọn tối ưu về mặt tính toán và dễ hiểu. Việc hiểu rõ ưu nhược điểm của từng thuật toán là cực kỳ quan trọng.
Tinh chỉnh siêu tham số (Hyperparameter Tuning): Chìa khóa nâng cao hiệu suất
Siêu tham số là các tham số được thiết lập trước khi quá trình huấn luyện bắt đầu, không được học từ dữ liệu. Ví dụ bao gồm tốc độ học (learning rate), số lượng lớp ẩn trong mạng nơ-ron, số lượng nơ-ron trong mỗi lớp, kích thước batch, và số epoch huấn luyện. Việc tinh chỉnh siêu tham số là một quá trình tối ưu hóa để tìm ra bộ giá trị tốt nhất giúp mô hình đạt hiệu suất cao nhất trên dữ liệu độc lập. Các kỹ thuật phổ biến để tinh chỉnh siêu tham số bao gồm tìm kiếm lưới (grid search), tìm kiếm ngẫu nhiên (random search), hoặc các phương pháp tối ưu hóa tiên tiến hơn như tối ưu hóa Bayes. Quá trình này thường tốn nhiều thời gian và tài nguyên tính toán nhưng lại mang lại sự khác biệt đáng kể về hiệu suất mô hình.
Đánh giá và tối ưu hóa hiệu suất mô hình
Sau khi mô hình được huấn luyện, việc đánh giá và tối ưu hóa hiệu suất là bước không thể thiếu trong AI Model Training để đảm bảo mô hình hoạt động như mong đợi và đáp ứng các tiêu chuẩn đã đặt ra. Đây là một quy trình lặp lại, đòi hỏi sự kiên nhẫn và phân tích kỹ lưỡng.
Các chỉ số đánh giá quan trọng: Đo lường sự thông minh của AI
Các chỉ số đánh giá hiệu suất mô hình AI phụ thuộc vào loại bài toán. Đối với bài toán phân loại, các chỉ số thường dùng bao gồm độ chính xác (accuracy), độ nhạy (recall), độ đặc hiệu (precision), điểm F1-score và đường cong ROC-AUC. Đối với bài toán hồi quy, các chỉ số như lỗi bình phương trung bình (MSE), lỗi tuyệt đối trung bình (MAE) và R-squared được sử dụng. Việc lựa chọn chỉ số phù hợp là rất quan trọng vì mỗi chỉ số phản ánh một khía cạnh khác nhau của hiệu suất mô hình. Ví dụ, trong y tế, độ nhạy cao quan trọng hơn độ đặc hiệu để tránh bỏ sót bệnh nhân mắc bệnh.
Khắc phục lỗi và cải thiện độ chính xác: Quy trình lặp lại không ngừng
Nếu hiệu suất mô hình chưa đạt yêu cầu, các chuyên gia cần quay lại phân tích, tìm hiểu nguyên nhân và thực hiện các cải tiến. Điều này có thể bao gồm việc thu thập thêm dữ liệu, làm sạch dữ liệu kỹ lưỡng hơn, thử nghiệm các thuật toán khác, điều chỉnh lại siêu tham số, hoặc thậm chí là thay đổi kiến trúc mô hình. Việc phân tích lỗi của mô hình giúp xác định các trường hợp mà mô hình hoạt động kém, từ đó đưa ra các giải pháp khắc phục cụ thể. Quy trình này là một vòng lặp liên tục của việc huấn luyện, đánh giá, phân tích và cải tiến cho đến khi đạt được hiệu suất mong muốn.
Thách thức và tương lai của AI Model Training
Mặc dù đã đạt được những thành tựu đáng kinh ngạc, quy trình AI Model Training vẫn đối mặt với nhiều thách thức và đang không ngừng phát triển để đáp ứng những yêu cầu ngày càng cao của thế giới công nghệ.
Vấn đề đạo đức và trách nhiệm trong AI
Một trong những thách thức lớn nhất hiện nay là đảm bảo tính công bằng, minh bạch và có trách nhiệm của các mô hình AI. Dữ liệu huấn luyện có thể chứa đựng những thành kiến vô thức của con người, dẫn đến việc mô hình AI đưa ra các quyết định thiên vị hoặc phân biệt đối xử. Việc AI Model Training cần phải chú trọng đến việc phát hiện và giảm thiểu các thành kiến này là cực kỳ quan trọng. Hơn nữa, khả năng giải thích (explainability) của các mô hình AI phức tạp, đặc biệt là mạng nơ-ron sâu, vẫn còn là một lĩnh vực nghiên cứu tích cực. Việc hiểu được tại sao AI đưa ra một quyết định cụ thể là rất cần thiết cho việc xây dựng niềm tin và trách nhiệm giải trình.
Hướng tới AI tự động hóa và học liên tục
Tương lai của AI Model Training đang hướng tới việc tự động hóa nhiều hơn các bước trong quy trình, từ lựa chọn thuật toán, tinh chỉnh siêu tham số đến đánh giá mô hình, thông qua các phương pháp như Auto-ML. Điều này sẽ giúp giảm bớt gánh nặng cho các nhà khoa học dữ liệu và tăng tốc độ phát triển AI. Hơn nữa, khái niệm học liên tục (continual learning) hay học trọn đời (lifelong learning) cũng đang được nghiên cứu mạnh mẽ, cho phép mô hình AI liên tục học hỏi từ dữ liệu mới mà không quên đi những kiến thức đã học trước đó, giúp chúng thích nghi tốt hơn với môi trường thay đổi. AI Model Training sẽ tiếp tục là một lĩnh vực năng động, liên tục đổi mới để tạo ra những hệ thống AI ngày càng thông minh, hiệu quả và có khả năng giải quyết các vấn đề phức tạp hơn trong tương lai.

{kind=link}